
Връщайки се към същността, пробивът на AIGC в уникалността е комбинация от три фактора:
1. GPT е реплика на човешки неврони
GPT AI, представен от NLP, е алгоритъм на компютърна невронна мрежа, чиято същност е да симулира невронни мрежи в кората на главния мозък на човека.
Обработката и интелигентното въображение на езика, музиката, изображенията и дори вкусовата информация са функции, натрупани от човека
мозъкът като „протеинов компютър“ по време на дългосрочна еволюция.
Следователно GPT естествено е най-подходящата имитация за обработка на подобна информация, тоест неструктуриран език, музика и изображения.
Механизмът на неговата обработка не е разбирането на значението, а по-скоро процес на прецизиране, идентифициране и асоцииране.Това е много
парадоксално нещо.
Алгоритмите за ранно семантично разпознаване на речта по същество създават граматичен модел и речева база данни, след което картографират речта в речника,
след това постави речника в граматичната база данни, за да разбере значението на речника и накрая получи резултати за разпознаване.
Ефективността на разпознаване на това базирано на „логически механизъм“ разпознаване на синтаксис се движи около 70%, като например разпознаването на ViaVoice
алгоритъм, въведен от IBM през 90-те години.
AIGC не е за игра по този начин.Същността му не е да се грижи за граматиката, а по-скоро да създаде алгоритъм на невронна мрежа, който позволява
компютър за преброяване на вероятностните връзки между различни думи, които са невронни връзки, а не семантични връзки.
Подобно на изучаването на майчиния ни език, когато бяхме млади, ние естествено го научихме, вместо да научим „подлог, сказуемо, обект, глагол, допълнение“,
и след това разбиране на параграф.
Това е моделът на мислене на AI, който е разпознаване, а не разбиране.
Това е и подривното значение на AI за всички модели на класически механизми – компютрите не трябва да разбират този въпрос на логическо ниво,
а по-скоро идентифицирайте и разпознайте връзката между вътрешната информация и след това я опознайте.
Например, състоянието на енергийния поток и прогнозирането на електрическите мрежи се основават на класическа симулация на електроенергийната мрежа, където математическият модел на
механизъм се установява и след това се събира с помощта на матричен алгоритъм.В бъдеще може да не се наложи.AI директно ще идентифицира и прогнозира a
определен модален модел въз основа на състоянието на всеки възел.
Колкото повече възли има, толкова по-малко популярен е класическият матричен алгоритъм, тъй като сложността на алгоритъма нараства с броя на
възли и геометричната прогресия се увеличава.Въпреки това AI предпочита да има едновременност на възли в много голям мащаб, тъй като AI е добър в идентифицирането и
предвиждане на най-вероятните мрежови режими.
Независимо дали става въпрос за следващата прогноза на Go (AlphaGO може да предвиди следващите десетки стъпки, с безброй възможности за всяка стъпка) или модалната прогноза
на сложни метеорологични системи, точността на AI е много по-висока от тази на механичните модели.
Причината, поради която електрическата мрежа в момента не изисква AI е, че броят на възлите в 220 kV и по-високи електрически мрежи, управлявани от провинциални
диспечирането не е голямо и са зададени много условия за линеаризиране и разреждане на матрицата, което значително намалява изчислителната сложност на
модел на механизма.
Въпреки това, на етапа на потока на мощността на разпределителната мрежа, изправен пред десетки хиляди или стотици хиляди захранващи възли, товарни възли и традиционни
матричните алгоритми в голяма разпределителна мрежа са безсилни.
Вярвам, че разпознаването на модели на AI на ниво дистрибуторска мрежа ще стане възможно в бъдеще.
2. Натрупването, обучението и генерирането на неструктурирана информация
Втората причина AIGC да направи пробив е натрупването на информация.От A/D преобразуване на реч (микрофон+PCM
вземане на проби) към A/D преобразуването на изображения (CMOS+цветно картографиране на пространството), хората са натрупали холографски данни във визуални и слухови
полета по изключително евтини начини през последните няколко десетилетия.
По-специално, широкомащабното популяризиране на фотоапарати и смартфони, натрупването на неструктурирани данни в аудиовизуалното поле за хората
при почти нулеви разходи и експлозивното натрупване на текстова информация в Интернет са ключът към обучението на AIGC – наборите от данни за обучение са евтини.
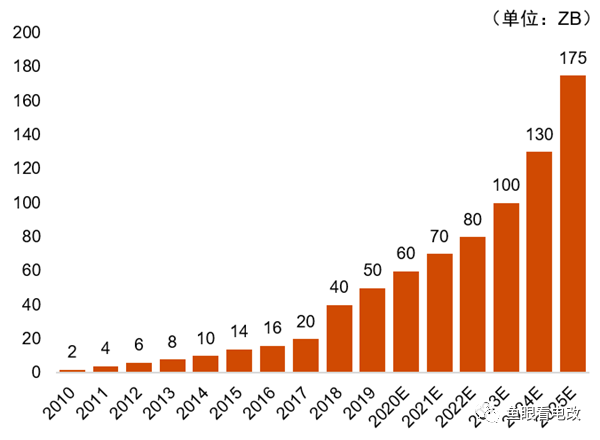
Фигурата по-горе показва тенденцията на растеж на глобалните данни, която ясно представя експоненциална тенденция.
Този нелинеен растеж на натрупването на данни е основата за нелинейния растеж на възможностите на AIGC.
НО повечето от тези данни са неструктурирани аудио-визуални данни, които се натрупват при нулева цена.
В областта на електроенергетиката това не може да се постигне.Първо, по-голямата част от електроенергийната индустрия е структурирани и полуструктурирани данни, като напр
напрежение и ток, които са точкови набори от данни от времеви редове и полуструктурирани.
Наборите от структурни данни трябва да бъдат разбрани от компютрите и изискват „подравняване“, като например подравняване на устройството – данните за напрежението, тока и мощността
на превключвател трябва да бъдат подравнени към този възел.
По-неприятно е изравняването на времето, което изисква изравняване на напрежението, тока и активната и реактивната мощност въз основа на времевата скала, така че
може да се извърши последваща идентификация.Има също посоки напред и назад, които представляват пространствено подравняване в четири квадранта.
За разлика от текстовите данни, които не изискват подравняване, абзацът просто се хвърля към компютъра, който идентифицира възможни информационни асоциации
сам.
За да се приведе в съответствие този проблем, като привеждането в съответствие на оборудването на данни за бизнес разпространение, привеждането в съответствие е постоянно необходимо, тъй като средата и
разпределителната мрежа за ниско напрежение добавя, изтрива и модифицира оборудване и линии всеки ден, а мрежовите компании харчат огромни разходи за труд.
Подобно на „анотацията на данни“, компютрите не могат да направят това.
Второ, разходите за събиране на данни в енергийния сектор са високи и са необходими сензори вместо мобилен телефон, за да говорите и да правите снимки.”
Всеки път, когато напрежението намалее с едно ниво (или съотношението на разпределението на мощността намалее с едно ниво), необходимата инвестиция в сензора се увеличава
поне с един порядък.За да се постигне разпознаване от страната на товара (капилярния край), това е още по-голяма цифрова инвестиция.
Ако е необходимо да се идентифицира преходният режим на електрическата мрежа, е необходима високопрецизна високочестотна дискретизация, а цената е още по-висока.
Поради изключително високите пределни разходи за събиране на данни и подравняване на данни, електрическата мрежа в момента не е в състояние да натрупа достатъчно нелинейни
нарастване на информацията за данни за обучение на алгоритъм за достигане на сингулярността на AI.
Да не говорим за отвореността на данните, невъзможно е за мощен AI стартъп да получи тези данни.
Следователно, преди AI е необходимо да се реши проблемът с наборите от данни, в противен случай общият AI код не може да бъде обучен да произвежда добър AI.
3. Пробив в изчислителната мощ
В допълнение към алгоритмите и данните, пробивът в уникалността на AIGC е и пробив в изчислителната мощ.Традиционните процесори не са
подходящ за широкомащабни едновременни невронни изчисления.Именно приложението на GPU в 3D игри и филми прави широкомащабни паралелни
възможно е изчисление с плаваща запетая+поточно предаване.Законът на Мур допълнително намалява изчислителните разходи за единица изчислителна мощност.
ИИ на електрическата мрежа, неизбежна тенденция в бъдещето
С интегрирането на голям брой разпределени фотоволтаични и разпределени системи за съхранение на енергия, както и изискванията за приложение на
виртуални електроцентрали от страната на натоварването, обективно е необходимо да се извърши прогнозиране на източника и натоварването за публичните разпределителни мрежови системи и потребителите
разпределителни (микро) мрежови системи, както и оптимизиране на енергийния поток в реално време за разпределителни (микро) мрежови системи.
Изчислителната сложност на страната на разпределителната мрежа всъщност е по-висока от тази на планирането на преносната мрежа.Дори за реклама
сложни, може да има десетки хиляди зареждащи устройства и стотици превключватели и търсенето на базирана на изкуствен интелект работа на микро мрежа/разпределителна мрежа
ще възникне контрол.
С ниската цена на сензорите и широкото използване на силови електронни устройства като полупроводникови трансформатори, полупроводникови ключове и инвертори (конвертори),
интегрирането на сензори, изчисления и контрол на ръба на електрическата мрежа също се превърна в новаторска тенденция.
Следователно AIGC на електрическата мрежа е бъдещето.Но това, което е необходимо днес, не е незабавно да се извади алгоритъм с изкуствен интелект, за да се правят пари,
Вместо това първо обърнете внимание на проблемите с изграждането на инфраструктурата за данни, изисквани от AI
Във възхода на AIGC трябва да има достатъчно спокойно мислене за нивото на приложение и бъдещето на мощния AI.
Понастоящем значението на изкуствения интелект на мощността не е значително: например фотоволтаичен алгоритъм с точност на прогнозиране от 90% е пуснат на спот пазара
с праг на търговско отклонение от 5%, а отклонението на алгоритъма ще унищожи всички търговски печалби.
Данните са вода, а изчислителната мощност на алгоритъма е канал.Както се случи, така и ще бъде.
Време на публикуване: 27 март 2023 г